Data Frame Library Preview
One of our core objectives in creating our Numerical Libraries for .NET was to try to close the gap between the exploratory phase of development and the implementation phase, when the results are incorporated into applications. We wanted to address the needs of one of the fastest growing categories of users: data scientists.
Several tools are available already, but few come close to fulfilling our objectives. R is the most widely used platform for data analysis. Unfortunately the interaction with .NET is painful at best. For Python users, pandas is an excellent choice. It has been around for a few years and in that time has really matured in terms of API and performance. But of course, it’s Python only.
Blue Mountain Capital recently released Deedle, an open source library for exploratory data analysis written in F# by the brilliant Tomas Petricek and others. The library is fairly complete and has a nice API. especially for F# users. Using F#’s interactive REPL with Deedle, it is truly possible to do interactive exploratory data analysis with .NET.
Although a good effort has been made to make the library easy to use from other languages like C# and VB.NET, it is still more awkward than it could be. However, as we’ll see, the biggest problem with Deedle is performance.
Our own library for exploratory data analysis, which is well on its way to completion, is still convenient but maintains a high level of performance comparable to, and sometimes exceeding, that of pandas. I wanted to give you a preview of what’s coming.
Data Frame basics
The basic object in data analysis is a data frame. A data frame looks a lot like a database table. It is a two-dimensional table where the values in each column must be the same, but values in different columns can have different types. It also has a row index and a column index. The column index is used to select specific columns, usually with strings as keys.
Similarly, the row index can be used to select rows, but it also enables automatic data alignment. Imagine two time series, where some dates that are present in one series may not be present in another. If you want to compute the difference between the values in the two series, you want to make sure that you are comparing values for the same date. Here’s a quick example:
var s1 = Vector<double>.Create(
new double[] { 1, 2, 3, 4 }, new string[] { "a", "b", "c", "d" }); var s2 = Vector<double>.Create( new double[] { 40, 50, 10, 30 }, new string[] { "d", "e", "a", "c" });
Console.WriteLine(s1);
Console.WriteLine(s2);
Console.WriteLine(s1 + s2);We first create two vectors indexed using some strings. You’ll notice that the second vector has an extra key (e), and another key (b) is missing. If we add the two vectors, here is what we get:
a: 11
b: -
c: 33
d: 44
e: -The result has a value for all five keys. It has added values with corresponding keys correctly. Where a key was present in only one vector, a missing value was returned.
All vectors in the Extreme Optimization Numerical Libraries for .NET may have an index, and all matrices may have a row and a column index. Any operations involving indexed arrays will automatically align the data on the indexes.
Indexes on vectors and matrices are weakly typed in that the type of the keys is not part of the type definition. The keys are stored as strongly typed collections, of course.
A data frame is different from an indexed matrix in two ways. First, not all elements must be of the same type. Different columns can have different element types. Second, the indexes on a data frame are strongly typed, while the columns are weakly typed. You can easily access rows and columns by key, but if you want a strongly typed column, you need to do a tiny bit of extra work:
var df = DataFrame.Create<string, string>(
new string[] { "First", "Second" }, new Vector<double>[] { s1, s2 });
Console.WriteLine(df);
var s3 = df["First"].As<double>() + 10.0;
Console.WriteLine(s3);This creates a data frame using the two vectors we used earlier. We then get the first column, get it as a double, and add 10 to it. The output:
df: s3:
First Second
a: 1 10 a: 11
b: 2 - b: 21
c: 3 30 c: 31
d: 4 40 d: 41
e: - 50 e: -Notice that the row index on the data frame once again contains all keys in the two indexes, and missing values have been inserted in a vector where the key was not present.
Titanic survivor analysis in 20 lines of C#
Let’s do something more complicated. The Deedle home page starts with an example that computes the percentages of people who survived the Titanic disaster grouped by gender. The code shown is currently 20 lines. Using our library, the C# code is also 20 lines, and would look like this:
var titanic = DataFrame.ReadCsv(filename);
// Compute pivot table of counts, grouped by Sex and Survived:
var counts = titanic
.PivotBy<string, int>("Sex", "Survived")
.Counts()
.WithColumnIndex(new string[] { "Died", "Survived" });
// Add a column that contains the total count:
counts["Total"] = counts["Died"].As<double>() + counts["Survived"].As<double>();
// Create the data frame that contains the percentages:
var percentages = DataFrame.Create<string, string>(
new Dictionary<string, object>() {
{ "Died (%)", 100 * Vector<double>.ElementwiseDivide(
counts["Died"].As<double>(), counts["Total"].As<double>()) },
{ "Survived (%)", 100 * Vector<double>.ElementwiseDivide(
counts["Survived"].As<double>(), counts["Total"].As<double>()) }
});After reading the data into a DataFrame from a CSV file, we can compute a pivot table that shows the count for each combination of Sex and Survived. We then add a column that computes the total number of people for each gender. Finally, we construct a new data frame by dividing the first two columns by the total column.
F# has somewhat more succinct syntax, thanks mainly to its better type inference and support for custom operators. We can do the same thing in just 14 lines:
let titanic = DataFrame.ReadCsv(filename)
// Compute pivot table of counts, grouped by Sex and Survived:
let counts = titan.PivotBy<string, int>("Sex", "Survived")
.Counts()
.WithColumnIndex([| "Died"; "Survived" |]);
// Add a column that contains the total count:
counts?Total <- counts?Died + counts?Survived
// Create the data frame that contains the percentages:
DataFrame.Create<string, string>([
("Died (%)" , 100.0 * counts?Died ./ counts?Total ) ;
("Survived (%)" , 100.0 * counts?Survived ./ counts?Total )])Down the road we will be adding some more F# extras.
Comparing Deedle and Extreme Optimization Performance
So, how does this code perform? Well, we added some timing code, making sure to ‘warm up’ the code so we’re only testing the actual running time and not time spent JIT’ing the code. Here is what we found on an older i7 930:
Platform: x86
Example from Deedle home page (100 iterations)
Extreme Optimization: 11.137 ms (0.1114 ms/iteration)
Deedle: 5395.866 ms (53.9587 ms/iteration)
Ratio: 484.49
Platform: x64
Example from Deedle home page (100 iterations)
Extreme Optimization: 11.049 ms (0.1105 ms/iteration)
Deedle: 8208.071 ms (82.0807 ms/iteration)
Ratio: 742.91That’s right: our implementation is around 500 times faster than Deedle. We were as surprised as anyone by these results. You just don’t get these kinds of performance differences very often. So we looked a bit further. We summarized our findings in a chart:
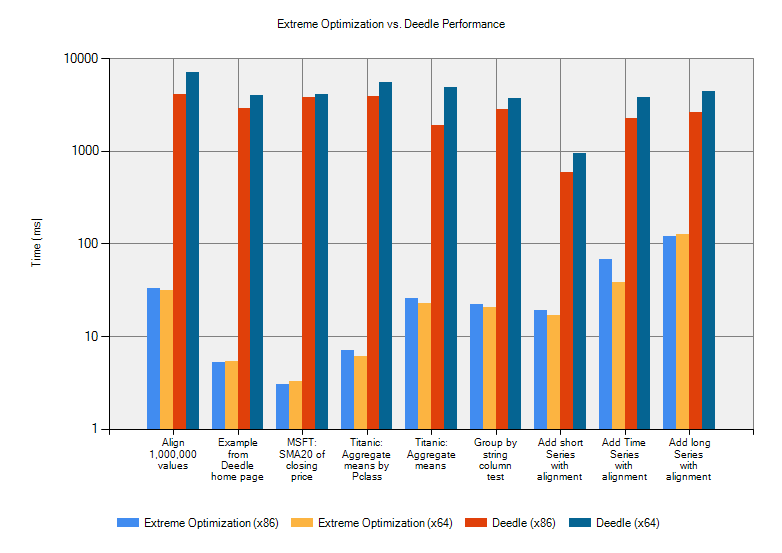
The chart compares running times (in ms) of 9 benchmarks using the Extreme Optimization library and Deedle running as both x86 and x64. Note that we had to use a logarithmic scale for the running time!
The conclusion: the Extreme Optimization library is 1 to 3 orders of magnitude faster than Deedle.
A couple of points on why these results aren’t entirely fair. First, the two versions don’t always do the same thing. For example: in the time series benchmark, we take advantage of the fact that the indexes are sorted to speed up the alignment. Verifying that the index is sorted is only done once. There are no doubt other cases where our code incurs a cost only once. Second, we use some specific optimizations that could be implemented in Deedle with relative ease. For example: we use an incremental method to compute the moving average, whereas Deedle re-computes the average for each window from scratch.
Still, a difference of 1-3 orders of magnitude is huge, and it begs for an explanation. I believe it’s rather simple, actually:
- Performance was not a priority in the development of Deedle, especially in this initial release. (We used the first official release version, 0.9.12.) We expect performance to improve as the library matures. Still, 3 orders of magnitude will be hard to make up. Which brings me to my other point:
- Sometimes, the F# language makes it a little too easy to write compact, elegant code that is very inefficient. For example: Types like tuples and discriminated unions are very convenient, but they are reference types, and so they have consequences for memory locality, cache efficiency, garbage collections…
Summary
Our upcoming data frame library will provide data scientists with a convenient way of interactively working with data sets with millions of rows. Compared to the only other library of its kind, Deedle, performance is currently 1 to 3 orders of magnitude better. A beta version of the library will be published soon. Contact me if you want to participate.